How to Select Your Final Models in a Kaggle Competition
Did your rank just drop sharp in the private leaderboard in a Kaggle competition?

I’ve been through that, too. We all learn about overfitting when we started machine learning, but Kaggle makes you really feel the pain of overfitting. Should I have been more careful in the Higgs Boson Machine Learning competition, I would have selected a solution that would gave me a rank 4 than rank 22.
I vow to come out with some principles systematically select final models. Here are the lessons learnt:
- Always do cross-validation to get a reliable metric. If you don’t, the validation score you get on a single validation set is unlikely to reflect the model performance in general. Then, you will likely see a model improvement in that single validation set, but actually performs worse in general. Keep in mind the CV score can be optimistic, but your model is still overfitting.
- Trust your CV score, and not LB score. The leaderboard score is scored only on a small percentage of the full test set. In some cases, it’s only a few hundred test cases. Your cross-validation score will be much more reliable in general.
- If your CV score is not stable (perhaps due to ensembling methods), you can run your CV with more folds and multiple times to take average.
- If a single CV run is very slow, use a subset of the data to run the CV. This will help your CV loop to run faster. Of course, the subset should not be too small or else the CV score will not be representative.
- For the final 2 models, pick very different models. Picking two very similar solutions means that your solutions either fail together or win together, effectively meaning that you only pick one model. You should reduce your risk by picking two confident but very different models. You should not depend on the leaderboard score at all.
- Try to group your solutions by methodologies. Then, pick the best CV score model from each group. Then compare these best candidates of each group, pick two.
- Example: I have different groups 1) Bagging of SVMs 2) RandomForest 3) Neural Networks 4) LinearModels. Then, each group should produce one single best model, then you pick 2 out of these.
- Pick a robust methodology. Here is the tricky part which depends on experience, even if you have done cross validation, you can still get burned: Sketchy methods of improving the CV score like making cubic features, cubic root features, boosting like crazy, magical numbers(without understanding it), etc, will likely be a bad model to pick even if the CV score is good. Unfortunately, you will probably have to make this mistake once to know what this means. =]
- Try to group your solutions by methodologies. Then, pick the best CV score model from each group. Then compare these best candidates of each group, pick two.
Applying the above principles to the recent competition Africa Soil Property Prediction Challenge, plus a bit of luck, I picked the top 1 and top 2 models.
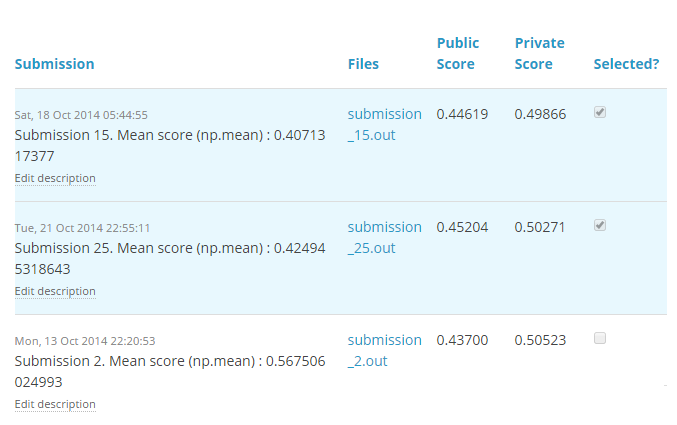
Sorted by private score
I ended up Top 10% with a rank of 90 by spending just a week time and mostly in Mexico in a vacation. I guess, not too bad?