Stacking, Blending and Stacked Generalization
Stacking, Blending and and Stacked Generalization are all the same thing with different names. It is a kind of ensemble learning.
In traditional ensemble learning, we have multiple classifiers trying to fit to a training set to approximate the target function. Since each classifier will have its own output, we will need to find a combining mechanism to combine the results. This can be through voting (majority wins), weighted voting (some classifier has more authority than the others), averaging the results, etc. This is the traditional way of ensemble learning.
In stacking, the combining mechanism is that the output of the classifiers (Level 0 classifiers) will be used as training data for another classifier (Level 1 classifier) to approximate the same target function. Basically, you let the Level 1 classifier to figure out the combining mechanism.
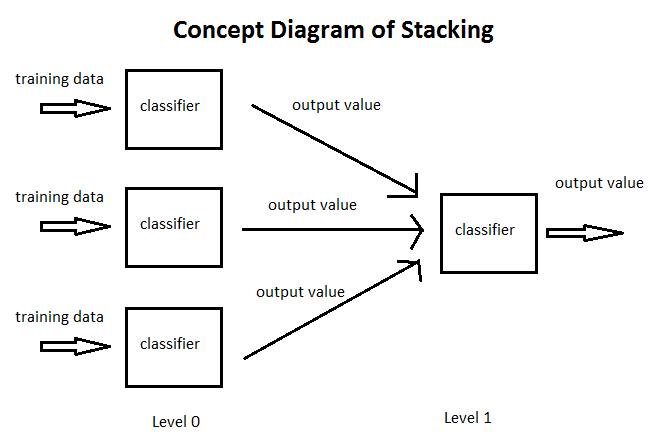
In practice, this works very well. In fact, it is most famously used in Netflix to achieve a very good score.
I have tested this technique on the Vertebral dataset with results below:
Random Forest with 1000 trees, accuracy = 0.883116883117.
Random Forest (10 trees), Extra Trees (20 trees), and a Gradient Boosting Tree (10 trees) stacked with a Logistic Regression, accuracy = 0.935483870968
You may find the code and dataset that demonstrates stacking here.